In this post, I will discuss about Multi Cast Routing, Routing in Ad-hoc networks: Route Discovery, Format of a ROUTE REPLY packet, and Congestion Control Algorithms in Computer Networks.
What is Multi Cast Routing?
There are few applications that need the involvement of far-away separated process to work together in groups. Better example is that of process involving group of different data base distributed in different systems. In such cases its required for one process to send message continuously to other members in the group. In a small group, message can be sent point to point, but if the group is large then the same approach will be expensive. Broadcasting approach can be used, but the same approach can be ineffective when there will be 1000 machines on a million node network, just because receivers will be not interested. Therefore it’s required to identify an approach that will send message to well defined group which are numerically large in number but small when compared with size of network. The approach of sending message is such case is called as Multicasting and the routing algorithm is called as Multi Cast Routing.
Group management is required for Multicasting. There should be a way to create and destroy the groups and allows the processes to join and leave groups. Routing algorithm is not concerned about the groups are created and destroyed. Routing algorithm is concerned with, when a process joins the group then its host should be informed about the same. It’s very much important for the router to know about which host belongs to which group. Routers must be informed about the processes joining or leaving the group either by host or router itself must sent a query to host periodically. Either router must learn about which of their hosts are in which group. Router tells their neighbours, so that the information propagates through subnet.
To perform multicast routing, every router calculates a spanning tree covering all the other routers. For example, in fig(a) we have two groups, 1 and 2. Some routers are attached to hosts that belong to one or both of these groups, as mentioned in figure. A spanning tree for the leftmost router as shown fig.(b).
When a process sends a multicast packet to a group, the first router examines its spanning trees and prunes it, removing all lines that donot lead to hosts that are members of the group. In fig.(c) its mentioned that the pruned spanning tree for group 1. Similarly Fig.(d) shows the pruned spanning tree for group 2. Multicast packets are forwarded only along the appropriate spanning tree.
There are other ways of pruning the spanning tree are possible. The simplest one can be used if link state routing is used and every single router is aware of complete topology, including hosts belong to which groups. Then the spanning tree can be pruned, starting at the end of each path, working toward the root, and removing all routers that do not belong to the group in question.
Because of distance vector routing, a different pruning strategy can be followed. Basic algorithm is reverse path forwarding. When a router with no hosts interested in a particular group and no connections to other routers receivers a multicast message for that group, and responds with prune message, telling the sender not to send any more multicasts for that group. When a router with no group members among its own hosts has received such messages on all its lines, it, can respond with PRUNE message.
One disadvantage of algorithm is that it scales poorly to large networks. Let’s say a network as n groups and with average of m members. For each group there will be m pruned spanning trees must be stored, for a total of mn trees. When there are large groups, storage is needed to store all the trees.
Alternative design will be using core-based trees. Single spanning tree per group is calculated, with the root near the middle of the group. To send a multicast message, a host sends it to the core, which then does the multicast along with spanning tree.
Routing in Ad-hoc networks:
Routing in Ad-hoc network is different from wired network because all the rules pertaining to fixed topologies, fixed and known neighbours, fixed relationship with IP address and location does not holds good. In ad-hoc network, routers can come and go in new place within the drop of a bit. As we know in a wired network if the router has valid path to a destination, then that path remains to be valid for indefinite time. With ad-hoc network, network topology will be changing all the time therefore path also changes spontaneously, without intimation.
Many routing alogrithms for ad-hoc network has been proposed.
Route Discovery: At any point of time, ad-hoc network can be shown by graph of the nodes (router +hosts). Two nodes are connected if they can communicate directly using their radios. Just because one among the two have stronger transmitter, its very much likely that A could be connected to B, but B could not be connected to A. We should not assume that just because two nodes are in the radio frequency of one another they will be connected to each other.
To describe the algorithm let’s consider an ad-hoc network as mentioned below, in which node A will be sending packet to node I. Ad-hoc on demand distance vector algorithm keeps a table for every node, keyed by destination, gives information about that destination, this also includes neighbour to which packet is being sent. If A does not finds the I in its table, then A will be searching for I. Algorithm has to discover the route to I. Property of discovering routes when required, is the one which make algorithm on demand.
- Range of A‘s broadcast. (b) After B and D have received A‘s broadcast. (c) After C, F, and G have received A‘s broadcast. (d) After E, H, and I have received A‘s broadcast. The shaded nodes are new recipients. The arrows show the possible reverse routes.
To identify the location of I, A will be form a new Route Request packet and broadcast it. This packet reaches to B and D as shown in Figure (a), Reason behind B and D are connected so that they can communicate from A. F is shown out of the circle because F cannot receive signal from A.
Format of Route Request is shown below:
| Source Address | Request ID | Destination Address | Source Sequence # | Destination Sequence # | Hop Count |
Format contains ip address of source and destination, which will identify that, is looking for whom. Request Id field is maintained separately for every single node and is incremented every time the request is broadcasted. Together, the Source address and Request ID fields uniquely identify the ROUTE REQUEST packet to allow nodes to discard any duplicates they may receive.
Apart from Request Id counter, every node maintains a second sequence number counter incremented every time a Route Request is sent or reply to someone else’s request is made. It is used to tell new routes from old routes. Source Sequence number is the sequence counter made from where the broadcast is made. Destination Sequence number is the most recent value of I’s sequence number that A has seen and obviously it will be zero if A has never seen I. Hop count will be keep the account of how many hops the broadcasted packet has made in order to reach its destination and is always set to 0.
When a Route Request packet arrives at a node, it’s processed in below mentioned steps:
- Source Address and Request ID is looked up in the local history table to verify the request has already been looked up and processed. If it’s duplicate then the request is discarded and process is stopped. If it’s not duplicated then it will recorded so that future duplicate request can be discarded.
- Receiver looks up the destination in its route table. If the fresh route to the destination is known, a ROUTE REPLY is sent back to source telling how to get the destination. Fresh means that destination sequence number is saved in the routing table is greater than or equal to Destination Sequence number stored in ROUTE REQUEST packet. If it is less, the stored route is older than the previous route the source had for the destination.
- Since the receiver does not know about the fresh route to the destination, it increments the hop count fields and rebroadcasts the ROUTE REQUEST packet. It also extracts the data from the packet and stores it as a new entry in its reverse route table. This information will be used to construct the reverse route so that the reply can get back to the source later. A timer is also started for the newly-made reverse route entry. If it expires, the entry is deleted.
Neither B nor D knows, where I is, so each of them creates a reverse route entry pointing back to A, as shown by the arrows in above figure and broadcasts the packet with Hop count set to 1. Broadcast from B reaches to C and D. C makes an entry for it in its reverse route table and rebroadcasts it. D rejects it as a duplicate. D’s broadcast is rejected by B. D’s broadcast is accepted by F and G and stored, as shown in Fig (c). After E, H, and I receive the broadcast, the ROUTE REQUEST finally reaches a destination that knows where I is, namely, I itself as shown in fig (d).
In response to the incoming request, I builds a ROUTE REPLY packet, as shown in below figure:
| Source Address | Destination Address | Destination Sequence # | Hop Count | Lifetime |
Format of a ROUTE REPLY packet
The Source address, Destination address, and Hop count are copied from the incoming request, but the Destination sequence number taken from its counter in memory. The Hop count field is set to 0. Lifetime field take care of the life of the route. This packet is unicast to the node that ROUTE REQUEST packet came from. It then follows the reverse path to D and finally to A. Hop count is incremented so the node can see how far from the destination (I) it is.
At every intermediate node, on the way back, packet is inspected. It is entered into the local routing table as a route to I if one or more of the following three conditions are met
- No route to I is known.
- The sequence number for I in the ROUTE REPLY packet is greater than the value in the routing table.
- The sequence numbers are equal but the new route is shorter.
In this way, all the nodes on the reverse route learn the route to I for free, as a byproduct of A’s route discovery. Nodes that got the original REQUEST ROUTE packet but were not on the reverse path (B, C, E, F, and H in this example) discard the reverse route table entry when the associated timer expires.
What are Congestion Control Algorithms?
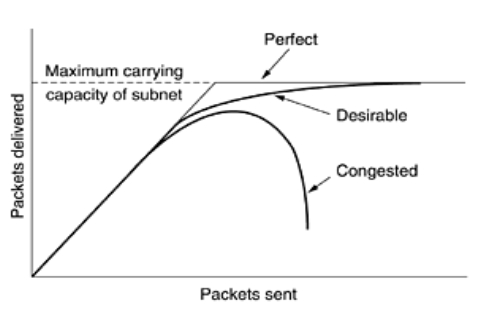
When too many packets are available in the subnet, performance degrades which is called as Congestion. Figure shows the symptom. When the number of packets dumped into the subnet by the hosts is within its carrying capacity, they are all delivered and the number delivered is proportional to the number sent. As traffic increases, the routers they begin losing packets are no longer able to cope. The performance collapses completely and almost no packets are delivered, at very high traffic.
When too much traffic is offered, congestion sets in and performance degrades sharply:
If all of a sudden, a queue builds up when a stream of packets begin arriving on three or four input lines and all need the same output line. If there is insufficient memory to hold all of them, packets will be lost. Adding more memory may help up to a point but if routers have an infinite amount of memory, congestion gets worse, because by the time packets get to the front of the queue, they have already timed out and replicas have been sent. All these packets will again be forwarded to the next router, increasing the load all the way to the destination.
Congestion is also caused by slow processes. Slow processes can build queues. Similarly, low-bandwidth lines can also cause congestion. Upgrading the lines but not changing the processors, or vice versa, sometimes helps a little, but frequently just shifts the bottleneck. Imbalance between parts of the system also causes congestion. The work of congestion control is making sure the subnet is able to carry the offered traffic. It is a global issue, involving the behavior of all the hosts, all the routers, the store-and-forwarding processing within the routers that diminish the carrying capacity of the subnet.